|
Ahmad Mustafa Anis I'm a Deep Learning Computer Vision Engineer at Roll.ai and was a participant of the highly competitive Fatima Fellowship (Sep 2024-Jun 2025) supervised by Dr. Wei Peng from Stanford University. I completed my Bachelors in Computer Science from International Islamic University Pakistan, advised by Dr. Muhammad Nadeem. I was an AI Fellow at the 14th Batch of PI School of AI with a scholarship worth 12,500€. I serve as a community lead (For Geo-Regional Asia) at Cohere Labs Community, led by Sara Hooker. In this role, I've hosted over 50 researchers from Asia to present their work at Cohere Labs Community, completed a study group on NYU Deep Learning by Yann LeCun. See my Resume here (Updated Jul 2025). Email / Twitter / Google Scholar / Hugging Face / Github / Medium / Linkedin |

|
ResearchI am interested in Deep Learning in general, and read literature from different fields. In-particular, I try to follow the research in the following areas:
|
Updates
My Talks & PresentationsIn-person TalksImage Generation with Diffusion Models
April 19, 2024
Dive deep into the world of Image Generation Diffusion models.
Impact: 50 Students and Professionals
View Event
Self Supervised Contrastive Deep Learning in Computer Vision
December 2, 2023
In this session we learned how self-supervised learning is leveraged in Computer Vision by diving into SimCLR by Google, SimCLR v2, and CLIP by OpenAI.
Impact: 1100 students / industry professionals
View Event
LinkedIn Post
Semantic Search using Deep Learning
March 19, 2023
Semantic search is a technique that uses deep learning algorithms to understand the context and meaning behind user queries, rather than just matching keywords. Attendees learned about the importance of semantic search, how it works, implementation in Python, and challenges.
Impact: Around 50 participants
View Event
Creating Interactive AI Applications: Deploying TensorFlow Models with Gradio and Hugging Face Spaces
February 26, 2023
Most models die in Jupyter Notebook and never reach a wider audience. With Gradio and Hugging Face Spaces, you can easily deploy your TensorFlow models with ease and create user-friendly interfaces for others to interact with.
Impact: Over 100 students, beginners, and industry professionals
View Event
Language Guided Recognition using CLIP (Machine Learning Focus Group)
December 31, 2022
Language Guided Computer Vision is now an active field of research in Computer Vision and surpases Supervised Learning. Learn how to use CLIP, a Language Guided Classifier by OpenAI by building a Semantic Image Search Engine.
Impact: Around 140 participants
View Event
How Convolutional Neural Networks work (Machine Learning Focus Group)
December 31, 2022
Convolutional Neural Networks are core-part of Computer Vision Deep Learning. They are widely used in real-world applications involving Object Classification, Object Detection, Object Segmentation, etc.
Impact: Around 140 participants
View Event
How Convolutional Neural Networks work
December 24, 2022
Convolutional Neural Networks are core-part of Computer Vision Deep Learning. This talk covers the history and theory of CNNs, their applications, and how easy it is to use it in Tensorflow 2.0.
Impact: Over 50 students, professionals and beginners
View Event
Video Privacy Application
March 2023
In-office session on the project Video Privacy Application discussing extensive findings on using OCR in real-time in our project.
Impact: 10 Machine Learning Engineers
Related Article
Introduction to AWS rekognition
April 6, 2023
In-office session on how to use AWS rekognition for multiple tasks and on live-stream.
Impact: 10 Machine Learning Engineers
Webinars"Data Science | Information, Trend, Road Map for Beginners"
April 16, 2023
An online webinar for University students discussing the important parts of Data Science and Machine Learning, roadmaps, general trends, tools and technologies, courses and how to get started with it.
Impact: 23 participants
Understanding SimCLRv2 by GoogleAI
April 12, 2023
An online webinar on SimCLRv2 and SimCLR by GoogleAI which showed the first time large scale application of self-supervised and semi-supervised learning on Images.
Impact: 15 participants
Language Guided Recognition | CLIP
November 19, 2022
An online webinar on Language Guided Recognition using CLIP by OpenAI which can perform zero shot classification and surpass the state of the art classifiers.
Impact: 20 participants
How Convolutional Neural Networks work
November 19, 2022
When it comes to Computer Vision, CNN plays a major role in creating an impact regarding how technology interacts with the world. From facial and handwritten recognitions to biometric authentications, CNN has been at the forefront of various breakthroughs within the Deep Learning space.
Impact: 100 participants
View Event
Hosted Talks at Cohere Labs Community (Selected only)As a community lead at Cohere Labs Community, I've hosted over 50 sessions inviting guest speakers from Stanford, MIT, Google, UC Berkeley, Allen Institute of AI, and other top institutions to present their research. Below are some of the most popular talks: For the complete list of hosted talks, visit the Cohere Labs Community YouTube Playlist. SigLIP: Sigmoid Loss for Language Image Pre-training
December 9, 2023
Talk by Lucas, a senior researcher at
Impact: 1085 views
Watch on YouTube
Why you should learn Mathematics for Machine Learning
March 19, 2024
Talk by Cheng Soon Ong, senior principal research scientist at the Statistical Machine Learning Group, Data61, CSIRO, and author of "Mathematics for Machine Learning."
Impact: 755 views
Watch on YouTube
GILL: Generating Images with Multimodal Large Language Models
September 8, 2023
Talk by Jing Yu Koh, a machine learning PhD student at Carnegie Mellon University.
Impact: 700 views
Watch on YouTube
Understanding diffusion models: A unified perspective
June 5, 2024
Talk by Calvin Luo, PhD student at Brown University.
Impact: 700 views
Watch on YouTube
Beyond A* Better Planning with Transformers via Search Dynamics Bootstrapping
June 13, 2024
Talk by Lucas Lehnert, a postdoctoral researcher as part of the FAIR team at Meta.
Impact: 139 views
Watch on YouTube
Deep Dive into the Mathematics of VAE
April 23, 2024
Talk by Dr. Matthew Bernstein, Principal Scientist, Computational Biology at Immunitas Therapeutics.
Impact: 294 views
Watch on YouTube
Pre-Doctoral AI Research Fellow - Fatima Fellowship
September 2024 - Present
Research fellowship advised by Dr. Wei Peng, Research Scientist at Stanford University.
Fellowship Website
Oxford Machine Learning Summer School (OxML) - MLX Fundamentals
April 2024
Selected participant for the prestigious Oxford Machine Learning Summer School.
AI Fellow - PI School of AI
December 2023
Got accepted as AI Fellow at the 14th Batch of PI School of AI with a scholarship worth 12,500€. Only participant selected from Pakistan.
Fellowship Website
Asian Community Lead - Cohere Labs Community
February 2023 - Present
Leading the Geo-Regional Asia community group at Cohere Labs Community, hosting over 50 researchers from Asia to present their work.
Cohere Labs Community Website
View Sessions
ML-Maths Community Lead - Cohere Labs Community
December 2023 - Sep 2024
Co-Lead the ML-Maths community group at Cohere Labs Community, organizing research talks and study groups.
Cohere Labs Community Website
Urdu Language Ambassador - AYA
June 2023
Served as Urdu Language Ambassador for AYA. Contributed 3 datasets and led data crowd sourcing.
AYA Paper
Contributed Datasets
Data Science Lead - Bytewise Fellowship
March 2023 - Present
Serving as Data Science Lead for Bytewise Fellowship.
Fellowship Website
NLP Lead - Bytewise Fellowship
June 2024 - Present
Serving as NLP Lead for Bytewise Fellowship.
Fellowship Website
|
Publications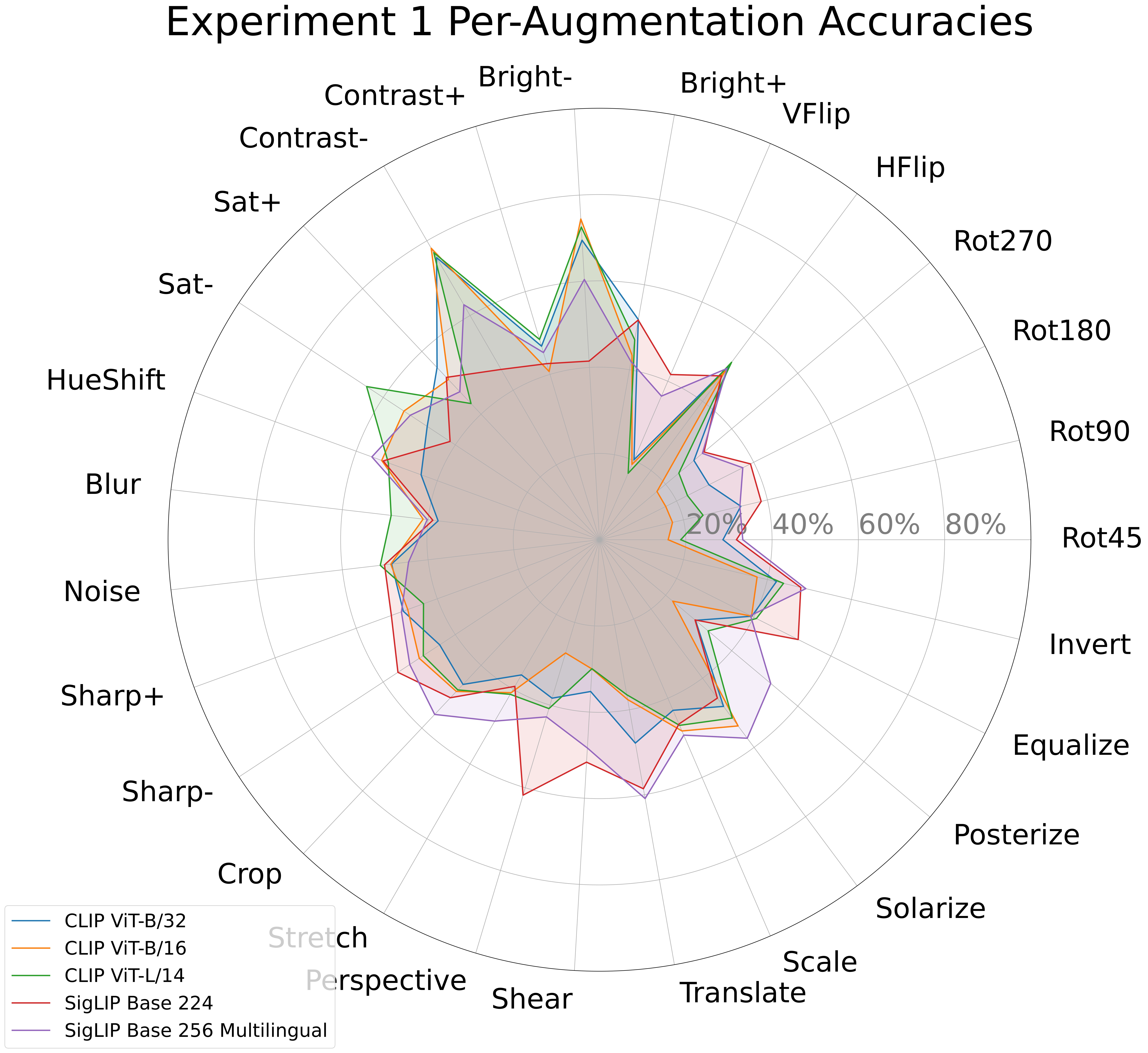
On the Limitations of Vision Language Models in Understanding Image Transforms
CVPR 2025 Computer Vision in the Wild Workshop
This paper investigates the image-level understanding of VLMs, specifically CLIP by OpenAI and SigLIP by Google. Our findings reveal that these models lack comprehension of multiple image-level augmentations.
|
Favourite PapersList of papers I really admire (and hope to do similar impactful work). |
|
Code from Jon Barron Website. |